Database Design Patterns for High-Performance Applications
Building a high-performance application starts with a strong database architecture. In this comprehensive guide, explore the most effective database design patterns used by modern SaaS platforms, enterprise systems, fintech applications, and large-scale web applications. Learn how normalization, denormalization, CQRS, shading, caching, partitioning, and read replicas can dramatically improve scalability, performance, reliability, and user experience.
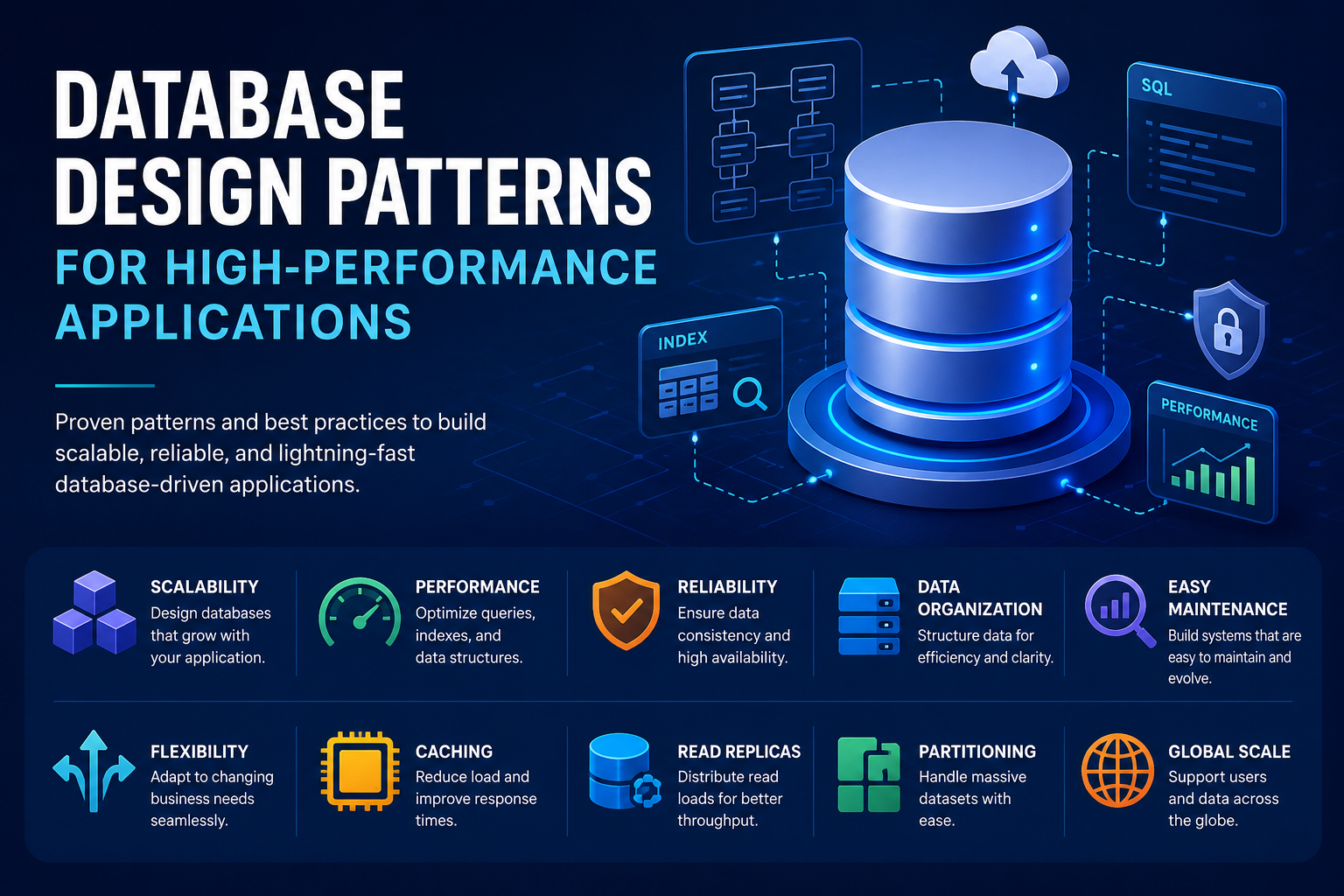
Key Takeaways
- Learn best practices and industry insights for technology
- Understand implementation strategies with real-world examples
- Get practical tips and actionable advice from industry experts
Database Design Patterns for High-Performance Applications: A Complete Guide for Modern Software Systems
Modern applications process massive amounts of data every second. Whether you're building a SaaS platform, eCommerce marketplace, fintech solution, healthcare application, social media platform, or enterprise management system, database performance directly impacts user experience, scalability, operational costs, and business success.
A poorly designed database can result in slow response times, bottlenecks, data inconsistencies, excessive infrastructure costs, and application failures under load. Conversely, a well-designed database architecture enables applications to scale efficiently while maintaining reliability and performance.
In this comprehensive guide, we will explore the most effective database design patterns used by high-performance applications. You'll learn how modern organizations structure data, optimize queries, improve scalability, and design databases capable of handling millions of users and transactions.
Table of Contents
- Introduction to Database Design Patterns
- Why Database Design Matters
- Understanding Database Performance
- Normalization Pattern
- Denormalization Pattern
- Master-Detail Pattern
- Repository Pattern
- CQRS Pattern
- Event Sourcing Pattern
- Sharding Pattern
- Partitioning Pattern
- Caching Pattern
- Materialized View Pattern
- Multi-Tenant Database Pattern
- Database Indexing Strategies
- Read Replica Pattern
- Database Security Best Practices
- Common Database Design Mistakes
- Choosing the Right Database Pattern
- Future Trends in Database Architecture
- Conclusion
Introduction to Database Design Patterns
Database design patterns are proven architectural solutions that address common challenges encountered when building software applications. These patterns provide reusable approaches for organizing, storing, retrieving, and managing data efficiently.
Rather than reinventing database structures for every project, developers leverage established patterns that have been validated in real-world production environments.
Companies such as Amazon, Google, Netflix, Uber, Airbnb, and Stripe rely heavily on database design patterns to maintain performance across billions of daily transactions.
The primary goals of database design patterns include:
- Improving scalability
- Enhancing performance
- Reducing query complexity
- Increasing maintainability
- Ensuring data consistency
- Supporting future growth
- Minimizing operational costs
Why Database Design Matters
Database architecture forms the foundation of every software system. Regardless of how advanced the frontend interface or backend infrastructure may be, inefficient database design can create significant bottlenecks.
Common problems caused by poor database design include:
- Slow page loading
- High server costs
- Query timeouts
- Data duplication
- Data inconsistency
- Maintenance challenges
- Scaling limitations
High-performance applications require databases capable of handling:
- Large data volumes
- Concurrent user requests
- Complex reporting queries
- Real-time transactions
- High availability requirements
- Global user distribution
Understanding Database Performance
Before exploring design patterns, it is important to understand the factors influencing database performance.
Query Performance
The speed at which data can be retrieved and processed significantly impacts application responsiveness.
Disk I/O Operations
Frequent disk reads and writes can become performance bottlenecks in large-scale systems.
Network Latency
Data transfers between applications and databases affect overall system speed.
Index Efficiency
Well-designed indexes reduce lookup times dramatically.
Concurrency Handling
Multiple simultaneous users require optimized transaction management.
Normalization Pattern
What is Normalization?
Normalization is the process of organizing data into multiple related tables to eliminate redundancy and improve consistency.
Example:
Users - UserID - Name - Email Orders - OrderID - UserID - TotalAmount
Benefits
- Reduced duplication
- Improved consistency
- Easier maintenance
- Smaller storage requirements
Challenges
- Increased joins
- Complex queries
- Potential performance overhead
Normalization is commonly used in ERP systems, banking platforms, CRM applications, and healthcare systems.
Denormalization Pattern
Denormalization intentionally duplicates data to improve read performance.
Example
Orders - OrderID - UserID - UserName - UserEmail - TotalAmount
Instead of joining user tables repeatedly, data is stored directly within order records.
Benefits
- Faster reads
- Reduced joins
- Improved reporting performance
Use Cases
- Analytics platforms
- Reporting systems
- Business intelligence tools
- High-traffic applications
Master-Detail Pattern
The Master-Detail pattern organizes data into parent-child relationships.
Example
Orders (Master) OrderItems (Detail)
This pattern provides clear separation between primary entities and related records.
Benefits
- Improved organization
- Better scalability
- Simplified management
Repository Pattern
The Repository Pattern abstracts database operations from business logic.
Advantages
- Cleaner architecture
- Improved testability
- Reduced coupling
- Easier maintenance
Popular frameworks such as Entity Framework, Hibernate, and Laravel Eloquent implement repository-like approaches.
CQRS Pattern
Command Query Responsibility Segregation
CQRS separates read operations from write operations.
Write Database
- Create
- Update
- Delete
Read Database
- Optimized queries
- Reporting
- Analytics
This architecture improves scalability for applications with significantly higher read traffic than write traffic.
Event Sourcing Pattern
Instead of storing only current state, Event Sourcing stores every event that changes data.
Example
Account Created Funds Deposited Funds Withdrawn Account Updated
The current state is reconstructed from event history.
Benefits
- Audit trails
- Historical tracking
- Improved compliance
- Event-driven architecture support
Sharding Pattern
Database sharding distributes data across multiple servers.
Example
Shard 1: Users 1-1,000,000 Shard 2: Users 1,000,001-2,000,000 Shard 3: Users 2,000,001-3,000,000
Benefits
- Horizontal scaling
- Reduced load
- Improved availability
- Better performance
Major platforms like Instagram and Twitter use sharding extensively.
Partitioning Pattern
Partitioning divides tables into smaller segments.
Types
Range Partitioning
Data divided by date ranges.
Hash Partitioning
Data distributed using hashing algorithms.
List Partitioning
Data separated based on predefined categories.
Benefits
- Faster queries
- Improved maintenance
- Better archival strategies
Caching Pattern
Caching stores frequently accessed data in memory.
Popular Technologies
- Redis
- Memcached
- Hazelcast
Benefits
- Reduced database load
- Faster response times
- Improved user experience
Netflix reportedly serves billions of cache requests daily.
Materialized View Pattern
Materialized views store precomputed query results.
Instead of recalculating expensive queries repeatedly, results are stored and refreshed periodically.
Ideal For
- Analytics dashboards
- Business reporting
- Data warehousing
Multi-Tenant Database Pattern
Multi-tenancy allows multiple customers to share infrastructure while maintaining logical separation.
Approaches
Shared Database Shared Schema
All tenants share tables.
Shared Database Separate Schemas
Each tenant receives a dedicated schema.
Separate Databases
Each tenant receives an isolated database.
Benefits
- Reduced costs
- Simplified management
- Improved scalability
Database Indexing Strategies
Primary Index
Unique identifier lookup.
Composite Index
Multiple columns indexed together.
Covering Index
Contains all required query fields.
Full Text Index
Optimized for search functionality.
Best Practices
- Index frequently searched columns
- Avoid over-indexing
- Monitor query performance
- Regularly rebuild fragmented indexes
Read Replica Pattern
Read replicas duplicate data from the primary database.
Benefits
- Load balancing
- Improved availability
- Disaster recovery support
- Better reporting performance
Database Security Best Practices
Encryption
Encrypt sensitive data both at rest and in transit.
Access Controls
Implement role-based permissions.
Audit Logging
Track all database activities.
Backup Strategy
Maintain automated backups and recovery plans.
Input Validation
Prevent SQL injection attacks through parameterized queries.
Common Database Design Mistakes
Over-Normalization
Excessive table splitting creates complex joins.
Under-Normalization
Too much duplication increases maintenance overhead.
Ignoring Indexes
Results in slow queries.
Poor Naming Conventions
Reduces maintainability.
Missing Scalability Planning
Creates future bottlenecks.
Choosing the Right Database Pattern
No single database pattern fits every application.
Consider:
- Application size
- User traffic
- Data complexity
- Reporting requirements
- Budget constraints
- Future growth projections
Recommended Combinations
- Normalization + Indexing for transactional systems
- Denormalization + Caching for content platforms
- CQRS + Event Sourcing for enterprise systems
- Sharding + Read Replicas for large-scale applications
Future Trends in Database Architecture
AI-Powered Database Optimization
Machine learning algorithms increasingly automate query optimization and indexing decisions.
Serverless Databases
Platforms such as Aurora Serverless and PlanetScale simplify infrastructure management.
Distributed SQL
Technologies like CockroachDB and YugabyteDB combine relational consistency with horizontal scalability.
Vector Databases
AI applications increasingly rely on vector databases for semantic search and retrieval.
Real-Time Analytics
Organizations demand instant insights from operational data.
Conclusion
Database design patterns are essential for building high-performance, scalable, and maintainable applications. By understanding and applying patterns such as Normalization, Denormalization, CQRS, Event Sourcing, Sharding, Partitioning, Caching, and Read Replicas, organizations can create robust systems capable of supporting modern business requirements.
The most successful applications rarely rely on a single pattern. Instead, they combine multiple architectural approaches to address specific performance, scalability, and reliability challenges.
As data volumes continue to grow and user expectations increase, database architecture will remain one of the most critical factors influencing software success. Investing time in selecting the right database design patterns today can significantly reduce technical debt, improve performance, and support long-term business growth.
Whether you are building a startup MVP, enterprise SaaS platform, eCommerce marketplace, fintech application, healthcare solution, or AI-powered system, the principles discussed in this guide provide a strong foundation for designing databases that perform efficiently under real-world conditions.
Sell Tech IND.
Sell Tech IND. Productions Team
We are a technology-driven company specializing in software development, web development, mobile apps, SaaS solutions, blockchain, AI, and digital marketing.
Stay Updated
Get the latest tech insights, tutorials, and industry news delivered straight to your inbox.
No spam, ever. Unsubscribe anytime.